https://dl.acm.org/doi/10.1145/3473334
The authors, D’Aberto et al. from Xilinx and Facebook, present an end-to-end system for deep-learning inference based on a family of specialized hardware processors synthesized on Field-Programmable Gate Array (FPGAs) to implement various flavours of Convolution Neural Networks
(CNN). The design is optimized for low latency, high throughput, and high energy efficiency. As the design is scalable it can be used on server-based FPGA accelerator cards as well as small , power constrained embedded devices. On the Xilinx Virtex Ultrascale+ VU13P FPGA, they achieve near maximum Digital Signal Processing frequency and greater than 80% efficiency of on-chip compute resources.
They describe a runtime system enabling the execution of a variety of DNNs for different input sizes and a compiler that reads, optimises, generates and estimates CNNs from several native frameworks (i.e., MXNet, Caffe, Keras, and Tensorflow). They also present
tools for partitioning a CNN into subgraphs for allocation of work to CPU cores and FPGAs.
The xDNN processor consists of the key components including:
- a systolic array or correlation unit
- a weight Direct Memory Access engine to schedule and transfer weight data from DDR,
- an Activation Memory (AM) for storing input/output tensors
- The spill controller schedules and manages the movement of large tensors between DDR and the AM.
- post-convolution pipelined blocks: activation (ReLU, PReLU), bias addition, and max pooling.

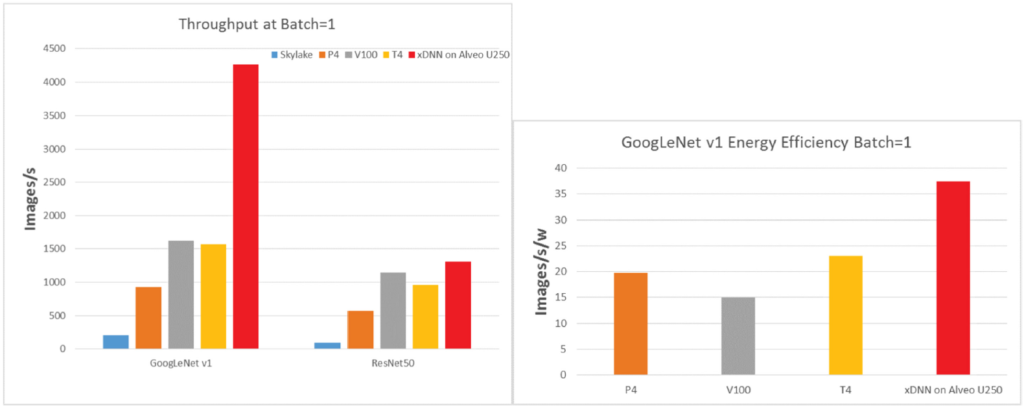
They show results achieving up to 4 times higher throughput and 3 times better power efficiency than comparative GPUs, and up to 20 times
higher throughput than the latest CPUs.